



Next: Access Control Lists in
Up: Appendixes
Previous: Appendixes
Contents
Index
Subsections
File Systems in Linux
|
Linux supports a number of different file systems. This chapter presents a brief overview of the most
popular Linux file systems, elaborating on their design concept,
advantages, and fields of application. Some additional information
about LFS (``Large File Support'') in Linux is also provided.
|
Glossary
- metadata
- A file system internal data structure that assures all
the data on disk is properly organized and accessible. Essentially,
it is ``data about the data.'' Almost every file system has its
own structure of metadata, which is partly why the file systems show
different performance characteristics. It is of major importance to
maintain metadata intact, because otherwise the whole data on the
file system could become inaccessible.
- inode
- Inodes contain various information about a file,
including size, number of links, date, and time of creation,
modification, and access, as well as pointers to the disk blocks
where the file contents are actually stored.
- journal
- In the context of a file system, a journal is an
on-disk structure containing a kind of log where the file system
stores what it is about to change in the file system's metadata.
``Journaling'' greatly reduces the recovery time of a Linux system
because it obsoletes the lengthy search process that checks the whole
file system at system start-up. Instead, only the journal is
replayed.
Major File Systems in Linux
Unlike two or three years ago, choosing a file system for a Linux
system is no longer a matter of a few seconds (``Ext2 or
ReiserFS?''). Kernels starting from 2.4 offer a variety of
file systems from which to choose. The following is an overview of how
those file systems basically work and which advantages they offer.
It is very important to bear in mind that there may be no file system
that best suits all kinds of applications. Each file system has its
particular strengths and weaknesses, which have to be taken into
account. Even the most sophisticated file system cannot substitute for
a reasonable backup strategy, however.
The terms ``data integrity'' or ``data consistency'', when used in
this chapter, do not refer to the consistency of the user space data
(the data your application writes to its files). Whether this data
is consistent must be controlled by the application itself.
[Setting up File Systems]Unless stated otherwise in this
chapter, all the steps required to set up or to change partitions
and file systems can be performed using the easy-to-use YaST
module.
Ext2
The origins of Ext2 go back to the early days of Linux
history. Its predecessor, the Extended File System, was
implemented in April 1992 and integrated in Linux 0.96c. The
Extended File System underwent a number of modifications
and, as Ext2, became the most popular Linux file system for
years. With the creation of journaling file systems and their
astonishingly short recovery times, Ext2 became less
important.
A brief summary of Ext2's strengths might help you to
understand why it was -- and in some areas still is -- the favorite Linux
file system of many a Linux user.
- Solidity
- Being quite an ``old-timer'', Ext2
underwent many improvements and was heavily tested. This may be the
reason why people often refer to it as ``rock-solid''. After a
system outage when the file system could not be cleanly unmounted,
e2fsck starts to analyze the file system data. Metadata
is brought into a consistent state and pending files or data blocks
are written to a designated directory (called lost+found).
In contrast to journaling file systems,
e2fsck analyzes the entire file system and not just the
recently modified bits of metadata. This takes significantly longer
than checking the log data of a journaling file system.
Depending on file system size, this procedure can take half an
hour or more. Therefore, you would not choose Ext2 for any
server that needs high availability. Yet, as Ext2 does
not maintain a journal and uses significantly less memory, it is
sometimes faster than other file systems.
- Easy upgradability
- The code for Ext2 is the strong
foundation on which Ext3 could become a highly-acclaimed
next-generation file system. Its reliability and solidity were
elegantly combined with the advantages of a journaling file system.
Ext3
Ext3 was designed by Stephen Tweedie. In contrast to all
other ``next-generation'' file systems, Ext3 does not
follow a completely new design principle. It is based on
Ext2. These two file systems are very closely
related to each other. An Ext3 file system can be easily
built on top of an Ext2 file system. The most important
difference between Ext2 and Ext3 is that
Ext3 supports journaling.
Summed up, Ext3 has three major advantages to offer:
- Easy and highly reliable file system upgrades from
Ext2
- As Ext3 is based on the Ext2
code and shares its on-disk format as well as its metadata format,
upgrades from Ext2 to Ext3 are incredibly easy.
Unlike transitions to other journaling file systems, such as
ReiserFS, JFS, or XFS, which can be
quite tedious (making backups of the whole file system and
recreating it from scratch), a transition to Ext3 is a
matter of minutes. It is also very safe, as the recreation of an
entire file system from scratch might not work flawlessly.
Considering the number of existing Ext2 systems that await
an upgrade to a journaling file system, you can easily figure out
why Ext3 might be of some importance to many system
administrators. Downgrading from Ext3 to Ext2
is as easy as the upgrade. Just perform a clean unmount of the
Ext3 file system and remount it as an Ext2 file
system.
- Reliability and performance
- Other journaling file systems
follow the ``metadata-only'' journaling approach. This means your
metadata will always be kept in a consistent state but the same
cannot be automatically guaranteed for the file system data
itself. Ext3 is designed to take care of both
metadata and data. The degree of ``care'' can be customized.
Enabling Ext3 in the data=journal mode offers
maximum security (i.e., data integrity), but can slow down the system
as both metadata and data are journaled. A relatively new approach
is to use the data=ordered mode, which ensures both data and
metadata integrity, but uses journaling only for metadata. The file
system driver collects all data blocks that correspond to one
metadata update. These blocks are grouped as a ``transaction'' and
will be written to disk before the metadata is updated. As a
result, consistency is achieved for metadata and data without
sacrificing performance. A third option to use is
data=writeback, which allows data to be written into the main
file system after its metadata has been committed to the journal.
This option is often considered the best in performance. It can,
however, allow old data to reappear in files after crash and recovery
while internal file system integrity is maintained. Unless you
specify something else, Ext3 is run with the
data=ordered default.
[Converting an Ext2 File System into an
Ext3 File System]Converting from Ext2 to
Ext3 involves two separate steps:
- Creating the journal
- Log in as SuSE @nohyphen root and
execute the command tune2fs -j. This creates an
Ext3 journal with the default parameters. If you
want to decide yourself how large the journal should be and
on which device it should reside, execute the command
tune2fs -J instead, together with the desired
journal options size= and device=.
More information about the tune2fs program is
available in its manual page (man 8 tune2fs).
- Specifying the file system type in /etc/fstab
- To ensure
that the Ext3 file system is recognized as such,
edit the file /etc/fstab, changing the
file system type specified for the corresponding
partition from ext2 to ext3. The change
takes effect after the next reboot.
ReiserFS
Officially one of the key features of the 2.4 kernel release,
ReiserFS has been available as a kernel patch for 2.2.x SuSE
kernels since SuSE Linux version 6.4. ReiserFS was designed
by Hans Reiser and the Namesys development team. ReiserFS
has proven to be a powerful alternative to the old Ext2. Its
key assets are better disk space utilization, better disk access
performance, and faster crash recovery. However, there is a minor
drawback: ReiserFS pays great care to metadata but not to
the data itself. Future generations of ReiserFS will include
data journaling (both metadata and actual data are written to the
journal) as well as ordered writes.
ReiserFS's strengths, in more detail, are:
- Better disk space utilization
- In ReiserFS, all data
is organized in a structure called B
 -balanced tree. The tree
structure contributes to better disk space utilization as small
files can be stored directly in the Btree leaf nodes instead
of being stored elsewhere and just maintaining a pointer to the
actual disk location. In addition to that, storage is not allocated
in chunks of 1 or 4 kB, but in portions of the exact size
needed. Another benefit lies in the dynamic allocation of inodes.
This keeps the file system more flexible than traditional file
systems, like Ext2, where the inode density has to be
specified at file system creation time.
-balanced tree. The tree
structure contributes to better disk space utilization as small
files can be stored directly in the Btree leaf nodes instead
of being stored elsewhere and just maintaining a pointer to the
actual disk location. In addition to that, storage is not allocated
in chunks of 1 or 4 kB, but in portions of the exact size
needed. Another benefit lies in the dynamic allocation of inodes.
This keeps the file system more flexible than traditional file
systems, like Ext2, where the inode density has to be
specified at file system creation time.
- Better disk access performance
- For small files, you will often
find that both file data and ``stat_data'' (inode) information
are stored next to each other. They can be read with a single disk
IO operation, meaning that only one access to disk is required to
retrieve all the information needed.
- Fast crash recovery
- Using a journal to keep track of recent
metadata changes makes a file system check a matter of seconds,
even for huge file systems.
JFS
JFS, the ``Journaling File System'' was developed by IBM.
The first beta version of the JFS Linux port reached the
Linux community in the summer of 2000. Version 1.0.0
was released in 2001. JFS is tailored to suit the needs of
high throughput server environments where performance is the ultimate
goal. Being a full 64-bit file system, JFS supports both
large files and partitions, which is another reason for its use in server
environments.
A closer look at JFS shows why this file system might
prove a good choice for your Linux server:
- Efficient journaling
- JFS follows a ``metadata
only'' approach like ReiserFS. Instead of an extensive
check, only metadata changes generated by recent file system
activity get checked, which saves a great amount of time in recovery.
Concurrent operations requiring multiple concurrent log entries can
be combined into one group commit, greatly reducing performance
loss of the file system through multiple write operations.
- Efficient directory organization
- JFS holds two
different directory organizations. For small directories, it allows
the directory's content to be stored directly into its inode. For
larger directories, it uses B
 trees, which greatly
facilitate directory management.
trees, which greatly
facilitate directory management.
- Better space usage through dynamic inode allocation
- For
Ext2, you have to define the inode density in advance (the
space occupied by management information), which restricted the
maximum number of files or directories of your file system.
JFS spares you these considerations -- it dynamically
allocates inode space and frees it when it is no longer needed.
XFS
Originally intended as file system for their IRIX OS, SGI
started XFS development back in the early 1990s. The idea behind
XFS was to create a high-performance 64-bit journaling file
system to meet the extreme computing challenges of today.
XFS is very good at manipulating large files and performs
well on high-end hardware. However, you will find a drawback even in
XFS. Like ReiserFS, XFS takes a great
deal of care of metadata integrity, but less of data integrity.
A quick review of XFS's key features explains why it may
prove a strong competitor for other journaling file systems in
high-end computing.
- High scalability through the use of allocation groups
- At
creation time of an XFS file system, the block device
underlying the file system is divided into eight or more linear
regions of equal size. Those are referred to as ``allocation
groups''. Each allocation group manages its own inodes and free
disk space. Practically, allocation groups can be seen as ``file
systems in a file system.'' As allocation groups are rather
independent of each other, more than one of them can be addressed by
the kernel simultaneously. This feature is the key to
XFS's great scalability. Naturally, the concept of
independent allocation groups suits the needs of multiprocessor
systems.
- High performance through efficient management of disk space
- Free space and inodes are handled by B trees inside the
allocation groups. The use of B trees greatly contributes to
XFS's performance and scalability. A feature truly unique
to XFS is ``delayed allocation''. XFS handles
allocation by breaking the process into two pieces. A pending
transaction is stored in RAM and the appropriate amount of space
is reserved. XFS still does not decide where exactly
(speaking of file system blocks) the data should be stored. This
decision is delayed until the last possible moment. Some
short-lived temporary data may never make its way to disk, because
it may be obsolete at the time XFS decides where to
actually save it. Thus XFS increases write performance
and reduces file system fragmentation. Because delayed allocation
results in less frequent write events than in other file systems, it
is likely that data loss after a crash during a write is more
severe.
- Preallocation to avoid file system fragmentation
- Before writing
the data to the file system, XFS ``reserves''
(preallocates) the free space needed for a file. Thus, file system
fragmentation is greatly reduced. Performance is increased as the
contents of a file will not be distributed all over the file
system.
Some Other Supported File Systems
Table A.1 summarizes some other file systems
supported by Linux. They are supported mainly to ensure compatibility
and interchange of data with different kinds of media or foreign
operating systems.
| File System Types in Linux |
| cramfs |
Compressed ROM file system: A compressed
read-only file system for ROMs. |
| hpfs |
High Performance File System: the IBM
OS/2 standard file system -- only supported in read-only mode. |
| iso9660 |
Standard file system on CD-ROMs. |
| minix |
This file system originated from academic projects on
operating systems and was the first file system used in Linux.
Nowadays, it is used as a file system for floppy disks. |
| msdos |
fat, the file system originally used by DOS,
is today used by various operating systems. |
| ncpfs |
file system for mounting Novell volumes over networks. |
| nfs |
Network File System:
Here, data can be stored on any machine in a network and access may be
granted via a network. |
| smbfs |
Server Message Block: used by products such
as Windows to enable file access over a network. |
| sysv |
Used on SCO UNIX, Xenix, and
Coherent (commercial UNIX systems for PCs). |
| ufs |
Used by BSD, SunOS, and
NeXTstep. Only supported in read-only mode. |
| umsdos |
UNIX on MSDOS: applied on top of a normal
fat file system. Achieves UNIX functionality (permissions,
links, long file names) by creating special files. |
| vfat |
Virtual FAT: extension of the fat file
system (supports long file names). |
| ntfs |
Windows NT file system, read-only. |
|
|
Large File Support in Linux
Originally, Linux supported a maximum file size of 2 GB. This was
enough before the explosion of multimedia and as long as no one tried
to manipulate huge databases on Linux. Becoming more and more
important for server computing, the kernel and C library were modified
to support file sizes larger than 2 GB when using a new set of
interfaces that applications must utilize. Nowadays, (almost) all
major file systems offer LFS support, allowing you to perform high-end
computing.
Table A.2 offers an overview of the current limitations of
Linux files and file systems for Kernel 2.4.
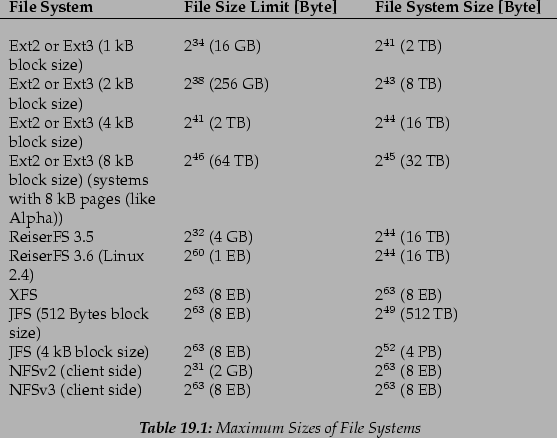
[Linux Kernel Limits]Table A.2 describes the
limitations regarding the on-disk format. The following kernel
limits (kernel version 2.4.x) exist:
- 32-bit systems: The maximum size of any file or block
device is limited to 2 TB. Using LVM to combine several
block devices allows you to handle larger file systems.
- 64-bit systems: File and file system sizes are limited to
2
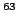 (8 EB). This limit may not yet be reached due to a lack of
hardware driver support.
(8 EB). This limit may not yet be reached due to a lack of
hardware driver support.
For More Information
Each of the file system projects described above maintains its own
home page where you can find mailing list information as well as
further documentation and FAQs.
http://e2fsprogs.sourceforge.net/
http://www.zipworld.com.au/~akpm/linux/ext3/
http://www.namesys.com/
http://oss.software.ibm.com/developerworks/opensource/jfs/
http://oss.sgi.com/projects/xfs/
A comprehensive multipart tutorial on Linux file systems can be found
at IBM developerWorks:
http://www-106.ibm.com/developerworks/library/l-fs.html
For a comparison of the different journaling file systems in Linux,
look at Juan I. Santos Florido's article at
Linuxgazette:
http://www.linuxgazette.com/issue55/florido.html.
Those interested in an in-depth analysis of LFS in Linux should try
Andreas Jaeger's LFS site:
http://www.suse.de/~aj/linux_lfs.html.
Next: Access Control Lists in
Up: Appendixes
Previous: Appendixes
Contents
Index
root
2003-11-05